What is Knowledge Engineering?
Think of a Semantic Graph as a new type of very fancy database.
In Chapter 1 of this series, we explained that Artificial Intelligence, “AI”, is not a technique, or a one fits all solution. It is a combination of computing techniques that are applied depending on what outcome is sought. It is a broad umbrella with many strands; some are progressing well and some are not very advanced at all.
About five years ago, a breakthrough was made with a technique called Deep Learning, a branch of Machine Learning that is based on the use of data structures called Neural Networks. Within months the hype had started with arguments that Deep Learning would deliver Artificial Intelligence.
In fact, it delivered what is known as pattern recognition, and substantially improved the state of the art in image and sound recognition. But like all Machine Learning techniques, it was clever but it was not ever going to deliver computers that had any degree of intelligence.
In the early hype three to four years ago, the terms Artificial Intelligence “AI” and Machine Learning “ML” were used interchangeably.
In the last two years, AI experts have begun to shout “Machine Learning is not AI” out of frustration, something the Venture Capital community may find out to their detriment.
Machine Learning is a group of techniques built on human knowledge. Its an advance on traditional computer programming, but still based on the coding by humans of mathematical formulae called algorithms.
An analogy would be that you arrive at hospital for heart surgery and you’re introduced to John. The nurse says...
“This is John. John will be doing your open-heart surgery. He doesn’t have any medical knowledge, but he’s watched your operation being done 650 times and we think he’s ready to do one himself. A real surgeon will supervise him.”
In computing, we call that “supervised Machine Learning”. It can be dangerous, especially if John isn’t very intelligent. Machine Learning is useful where you can expect consistency. It is the computing behind driver-less cars; only effective and safe where conditions are consistent.
Recently, AI experts have sought to address the early hype of Machine Learning.
"For most problems where deep learning has enabled transformationally better solutions (vision, speech), we’ve entered diminishing returns territory in 2016–2017."
[François Chollet, Google, author of Keras neural network library, December 18, 2017]
Nowadays, it is more common to hear or read of people discussing “Machine Learning and AI” and then continue on to talk about what Machine Learning is, but not many of them explain what AI is. The chances are that they don’t actually know.
Although it has been known for at least three decades that a computer cannot be intelligent without having access to knowledge that it understands by itself, without human intervention, the means by which that is best achieved has been subject to considerable debate
.
In 1999 Tim Berners-Lee (the inventor of the World Wide Web in 1989) and his colleagues at the Massachusetts Institute of Technology (MIT) introduced an incomplete architecture for the concept of a ‘Semantic Web’, a concept that would enable the World Wide Web to be ‘intelligent’.
He said “I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web, the content, links, and transactions between people and computers.
A Semantic Web, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The intelligent agents’ people have touted for ages will finally materialize.”
Five years later, Sir Tim Berners-Lee (knighted in 2004) expressed disappointment at the lack of progress with his “simple idea” of an intelligent Web.
What Berners-Lee may not have realized is that, for most of us, the proposed model for his intelligent web “dream” was not “simple”. Building computer technology that mimicked a very complex computer such as a human brain, even at a rudimentary level, required a very complex mathematical model on which to model the knowledge repository.
Early attempts at making the Berners-Lee dream a reality encountered myriad challenges and, outside of academia, were largely abandoned.
How to represent computer understandable knowledge was the core challenge, and the subject of much debate within the very few institutions that remained engaged in the leading research.
“Knowledge representation and reasoning is the field of AI dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language.
Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge in order to design formalisms that will make complex systems easier to design and build.
"Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning, such as the application of rules or the relations of sets and subsets.” Wikipedia
Berners-Lee proposed knowledge representation and reasoning for his intelligent agents based on “Semantic Graphs”, a sophisticated type of database (also known as a Knowledge Graph or a Semantic Knowledge Graph).
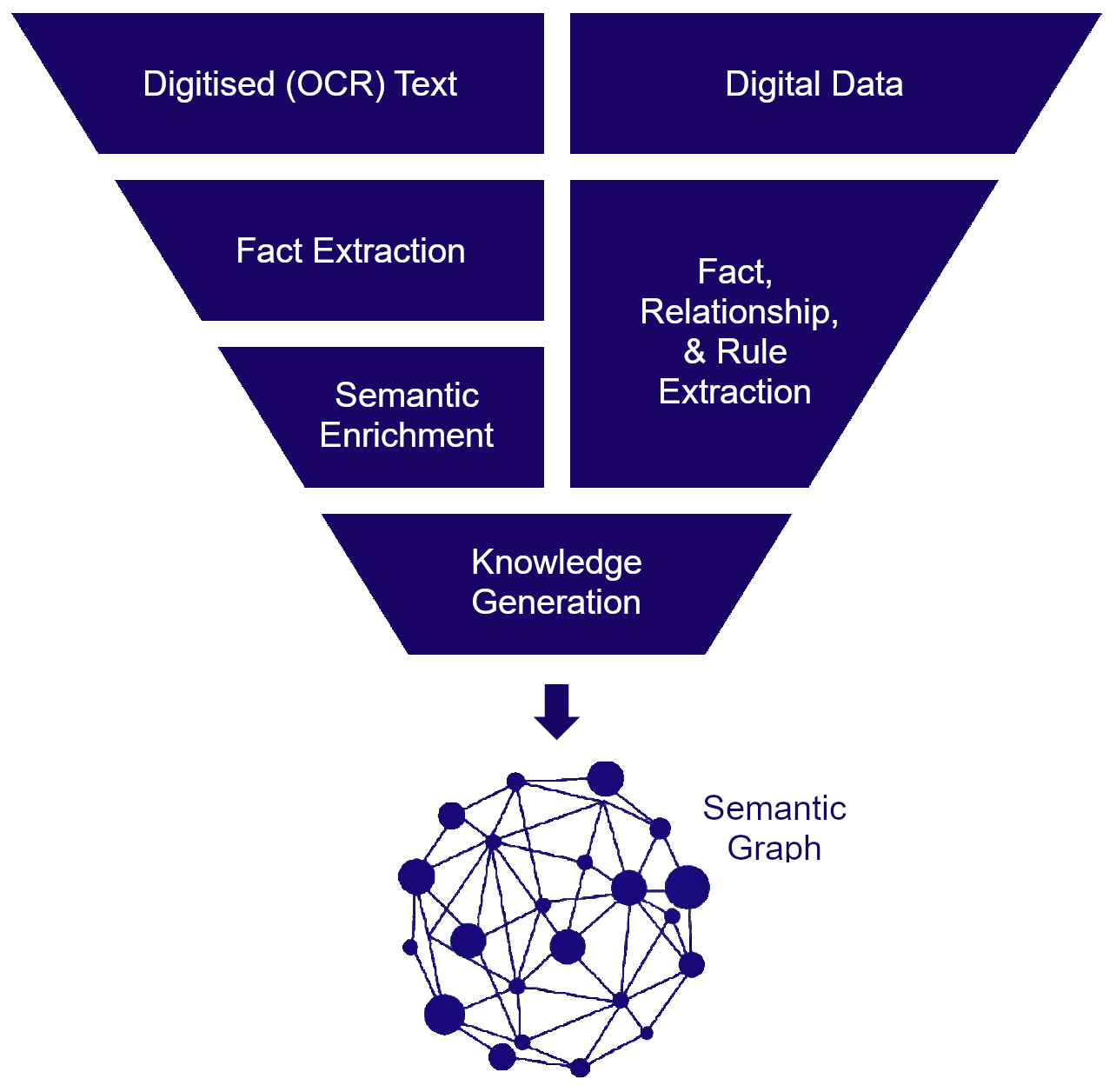
Semantic Graphs utilise two data models — the Resource Description Framework “RDF” data model and the Ontology data model. RDF is a data model for representing facts and Ontologies are a data model for defining the “rules and relations of sets and subsets” of facts. The Ontology data model is based on the mathematical study of Topology (Set Theory).
Humans accumulate knowledge by accumulating facts and understanding the rules and relationships between those facts, such relationships sometimes involving considerable complexity.
The Semantic Graph data models facilitate computer knowledge representation and reasoning in a similar fashion to mimic human knowledge accumulation, with facts represented in RDF, and Ontologies defining the rules and relationships between those facts.
It is not the purpose of this article to delve into the technicalities of the Semantic Graph data models suffice to say that they enable the most sophisticated way to represent things in a way that a computer can understand, by itself.
Further, they allow computers to infer new knowledge, to “automate various kinds of reasoning”, mimicking the human brain in understanding very complex things, abstract and real, but at a low level of reasoning compared to a human.
Think of a Semantic Graph as a new type of very fancy database that’s the closest we can get to a computer brain at this point in time, with the reasoning power of a child under three. It understands things and can perform basic reasoning, but it isn’t the “deep reasoning” that we would like. That level of intelligence is probably 30 to 50 years away.
There’s was a problem though. The Semantic Graph architecture proposed by Berners-Lee et al was missing critical components, and other proposed components were not fit for purpose.
In the years following the Berners-Lee proposal, most software vendors and start-ups found it too challenging and sought alternative approaches to building a Graph database suitable for computer knowledge.
These various alternative approaches have become known as “Properties Graphs”.
Watch - The Year of the Graph.
Meanwhile, Berners-Lee had founded the World Wide Web Consortium, “W3C”, to develop standards for the World Wide Web, as well as for the Semantic Web that was the subject of his dream. Some software vendors and a very few start-ups persevered to implement the many standards developed for Semantic Graphs, Ontologies and RDF.
Some, like us, also sought to develop high level user interfaces to the complex components so that complexity could be automated ‘under the covers’.
Our objective was to make sophisticated descriptions of things, that Semantic Graphs facilitate, available to medium skilled data scientists and administrators, without the need for them to have a mathematics degree or a PhD.
We sought to deliver to enterprises, individuals and society the Berners-Lee dream, and all the benefits that thirty years of research and standards-setting promised.
So, what are the benefits that Semantic Graphs have over Properties Graphs?
- Support for automated integration of structured data sources.
- Support for automated integration of unstructured data sources (text, video, audio) using OCR, Machine Learning, and Natural Language Processing for sophisticated knowledge discovery.
- Simple (putative) ontologies can be automatically generated from the Semantic Graph data and then enriched using ontology editors.
- Able to provide for the most complex and sophisticated descriptions of any Graph data model, a mandatory requirement for automated and robust AI.
- Can update data in existing Semantic Graphs dynamically and quickly.
- Can discover new knowledge using common Inferencing Engines.
- Utilize the Linked Open Data standard to link to one unique version of the truth (via URIs/URLs) internally and externally.
- Provide superior data integration and interoperability with ontologies that define the meaning of concepts, phrases and words across multiple environments.
- A query language, called “SPARQL”, compatible with multiple internal and external data source technologies removing the need to migrate data before you can query it.
- Ontologies and RDF used to define knowledge are shared, reusable and editable between knowledge experts, e.g. in medical research.
- Thirty years of standards setting provide portability of Graph content (including ontologies (rules) and RDF (facts)) between Semantic Graph vendors, protecting your investment.
- A standardized query language in the style of SQL, further aiding portability, by avoiding proprietary query languages that Property Graphs have.
The above benefits are far from trivial, they go to the heart of why Semantic Graphs are strategic and tactical, while alternatives are more tactical and potential dead ends.
"Property Graphs are easy to get started with. People think RDF based Knowledge Graphs are hard to understand, complex and hard to get started with. There is some truth to that characterization." Source.
People think RDF is a pain because it is complicated. The truth is even worse. RDF is painfully simplistic, but it allows you to work with real-world data and problems that are horribly complicated. Source.